
Port-Channel Load Balancing off of FEX's on Nexus 7000
At the enterprise I spend most of my time on-site at, we’ve been having problems with host facing port-channels whose members are on a fabric extender.
Our situation is this - we have fabric extenders (FEX’s) that are connected to Nexus 7000’s. Some of the host connections on the FEX’s are bundled together in port-channels going to the host. This is done for performance reasons in some instances - the hosts need to send or receive more traffic than a single link can carry
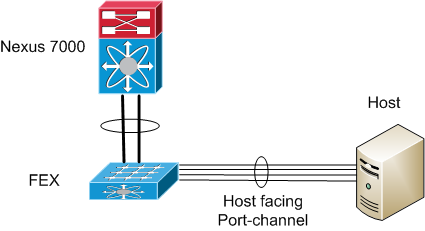
The server folks noticed that all traffic was being sent to them over a single link. The stats on the switch confirmed that was the case. Although all of the links were in the port-channel (and the host was sending traffic over all four of the links), the switch was sending all traffic on a single link. We saw this on all of our Nexus 7000’s with FEX’s and host facing port-channels.
A switch generates a hash based on the source and destination addresses listed in the frame, and uses the value of that hash to determine which member of the port-channel to transmit the frame out on. You can generally choose which addresses to use as inputs into the hash (the source / dest MAC addresses, source / dest IP’s, source / dest TCP or UDP ports, etc). Depending on where in the network the port-channel is, and the type of traffic flows going across it, it is certainly possible for all of the traffic to end up on one link. However, we were using the source and destination IP address and source and destination Layer 4 port as inputs to the hash algorithm. Given the traffic flows and number of connections going across this link, we were extremely confident that this should not be happening.
As a useful troubleshooting tool, you can manually run the hash algorithm for a particular port channel from the CLI on a Cisco switch. The command (on Nexus switches) is “show port-channel load-balance forwarding-path”. You’ll need to provide it with all of the relevant addresses for a given frame, and it will output which port that frame would have been transmitted on. The output from this command conflicted with what we were actually seeing interface utilization wise.
Through another organization, we talked with Cisco at the beginning of the year about this issue and got nowhere. I submitted a TAC case directly last week, and got a solution within a couple days.
This is due to a bug in NX-OS. We’re experiencing this issue on 5.2(3a). Based on what Cisco has said, it sounds like its also present in some versions of 6.1 as well. It is fixed in 5.2(9), and the as of yet un-released 6.1(4).
Based on the last update date on the bug article, and that this is only fixed in the very latest code, I’m guessing this bug was only fairly recently uncovered. While this isn’t an extremely critical bug - I do find it surprising that this bug wasn’t caught earlier. It seems like this kind of issue would affect a lot of people - we can’t be the only ones using port-channels to hosts off of FEX’s.
As far as I know, there’s not really a work-around, other than upgrading to NX-OS 5.2(9). The “work-around” we used when we initially discovered this problem was to split the port-channels into individual links with separate IP’s. The server team then manually pointed clients at the different IP addresses to achieve load balancing of the physical links. Not a great solution - it involved a lot of manual work, and isn’t as scalable management wise, but it worked in our situation.