
Data Center Server Access Topologies: Part 1, Logical Interface Config on Servers
Edit: Here are the final links to all four of the articles in my Data Center Server Access series of posts: Data Center Server Access Topologies: Part 1, Logical Interface Config on Servers
Data Center Server Access Topologies: Part 2, Cabling Topology
Data Center Server Access Topologies: Part 3, Switch Technologies
Data Center Server Access Topologies: Part 4, Uplinks
I intend to make a series of posts regarding different topologies for server access connectivity in the data center. There are a lot of new technologies out there for the access layer in the data center. I’m planning on splitting this into four posts, though some of the topics overlap a bit:
- Logical interface configuration on server (this post)
- Access switch physical topology
- Access switch technologies
- Upstream Connectivity from Access Switches
I’ll stay away from things like VXLAN and EVB for now in these posts. There’s not yet a whole lot of equipment that supports those technologies, and it’s still kind of up in the air from my perspective how we will adapt data center networking to integrate server virtualization. None of the solutions currently available appear terribly compelling in my opinion.
Logical Interface Configuration on Servers
There are a number of different ways that a server can handle multiple connections. A lot of this varies based on operating system. Some options require specific support and configuration on the switches, and some operate independently of that.
It’s also worth considering what happens during a failure. Connectivity to an IP address relies on the ARP table on L3 devices (IP -> MAC address resolution), and the MAC address table on each L2 device (MAC address -> switchport resolution). With many configuration options, one or both of those tables will have to be updated during a failure for traffic to reach the host via the remaining connection.
Single Homed Connection
A server can just have a single connection up to a switch. Obviously, this by itself provides no means of HA. If you have external HA mechanisms (like application load balancing, or job schedulers for HPC environments), it might be acceptable to use single homed servers. Particularly in HPC environments, where it’s more acceptable to trade some resiliency/high availability for greater capacity this might be an option to consider.
In addition to have several single points of failure (NIC, cable, switchport / switch itself), this makes doing maintenance on the switch itself difficult.
My thinking is that single homed connections should live on separate switches in the data center than dual homed devices. This makes it easier to do maintenance on the rest of the switches (that only host multi-homed devices). The switches dedicated to single homed devices should probably have some HA capabilities built in (like dual supervisors, ISSU, etc). If you’re using Cisco’s Fabric Extenders, you probably should consider having the FEX’s dual-homed.
Some devices (particularly appliances or embedded devices) might only support a single homed connection. So, realistically there are probably a few devices in any data center that can only have a single connection.
Pro’s:
- Simple
- Will work with any server and switch
Con’s:
- No HA
- No load balancing
- Any maintenance on the switch is disruptive
Active / Standby NIC’s
The simplest method of handling multiple connections on a server is simply to use only one of them at a time. One connection will be actively used for both transmitting and receiving traffic. The other NIC will not be used at all, unless the active NIC fails.
During a failure event, the either the new active NIC can take over the MAC address from the other NIC, or the new NIC can send out a gratuitous ARP (GARP) to notify hosts of the new IP -> MAC address mapping. In the first case, the MAC address tables in the switches will get updated to point to the new switchport for the existing MAC address. In the second case, the ARP tables for any device in that subnet that talks to
In Linux, this is configured as mode 1 bonding. Windows currently does not natively support NIC bonding. Typically bonding is handled through drivers provided by NIC vendors.
One item that should be mentioned is the risk of black holing traffic, depending on how your operating system or NIC checks for failure. This is a real world issue that affects most of these options (except port-channels). Typically, software assumes that if the link is physically up, it’s good. This can lead to traffic being black holed if the access switch loses its upstream connectivity:
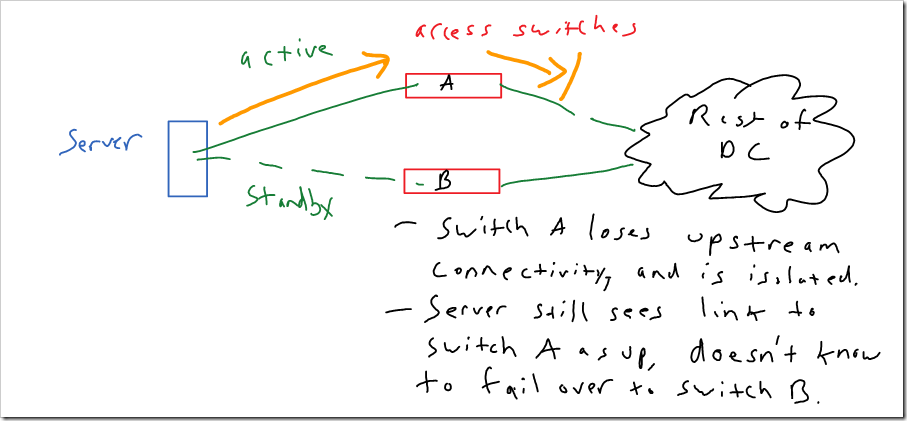
Many access switches have a feature called link state tracking. With link state tracking, if the switch loses its uplinks, it will shut down its access ports to force servers to fail over to another connection. With Cisco products - this is supported on the Nexus 7k, Catalyst 4500, 4900, 3750, 3650, and 2960. It is not supported on the Catalyst 6500, Nexus 3000, or Nexus 5000 unfortunately.
Linux does support an additional check beyond the physical interface status with ARP monitoring. It verifies that ARP broadcasts are being received by all NIC’s. I’ve not personally used this - but it sounds like a reasonable method (certainly better than just relying on the physical link status).
Pro’s
- No switch configuration needed
- High availability / failover across multiple switches
Cons
- No load balancing
Multiple IP addresses, multiple MAC’s
Another method is to use multiple IP addresses on the host with different MAC addresses. Each MAC address is bound to a particular NIC on the server. So, under normal (non-failure) circumstances, traffic for each IP only uses a single connection. The network doesn’t see the same source MAC address coming into multiple ports, and other devices in the subnet always communicate with the same MAC address for each IP.
Both connections are simultaneously used at the same time. Load balancing is done based on the IP addresses on the host. This will be less desirable than load balancing based on L4 characteristics in most environments. If 1G links are used for instance, each IP address on the host can use no more than 1G, regardless of how many separate TCP/UDP connections are made.
This also doesn’t require the participation or any configuration of the access switches. The connections can be made to separate access switches for greater resiliency. This approach is commonly used by VMware hosts. It’s well suited for virtualized environments, where they will nearly always going to be multiple VM’s on a host each with their own IP and MAC address.
In addition to failing over purely based on the physical interface status, VMware also supports using “beaconing” for failover. Unfortunately, this requires at least 3x NIC’s on the subnet for each VMware host. During a failure of a single connection, two of the NIC’s will still be able to see eachother’s beacons. The third NIC won’t be able to though (and the other two NIC’s will not see the beacon’s from the third NIC). So the host will know which NIC to take out of service. With only 2x NIC’s, neither NIC would see the advertisements from the other during a failure, so the host wouldn’t be able to determine which NIC is isolated.
I think probing the default gateway would be a much better and simpler option than beaconing (and would work with only 2x NIC’s). To my knowledge, this is currently not possible with VMware. Each NIC could simply ping the default gateway. If one NIC can no longer ping the default gateway on a subnet, but the other one can - it should take down the first NIC. This wouldn’t cover every possible scenario, but I think it would cover most of the real world failure scenarios.

Pro’s:
- No special configuration needed on switch
- HA / failover across multiple switches
- Active / Active - both NIC’s can be utilized at same time
Con’s:
- Load balancing less granular than L4 based hashing
- Not useful for non-virtualized hosts with single IP’s
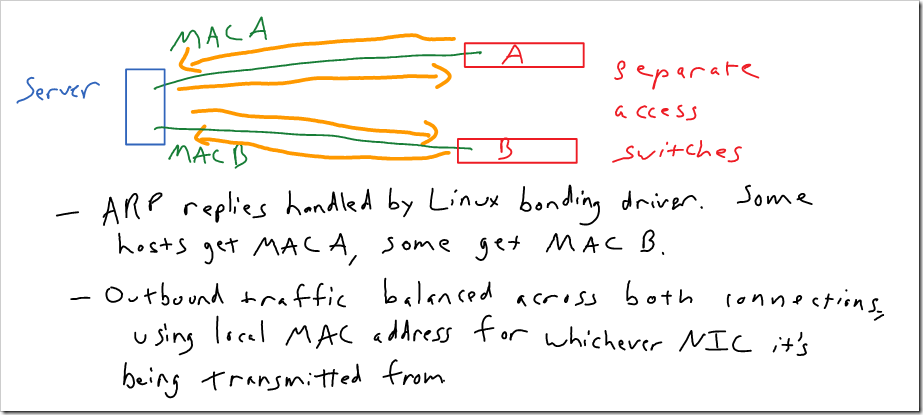
Linux Transmit / Adaptive Load Balancing
These are special bonding modes in Linux. Other systems might support similar methods. Both of these methods can be used across separate switches, and don’t require any specific configuration on the switch side.
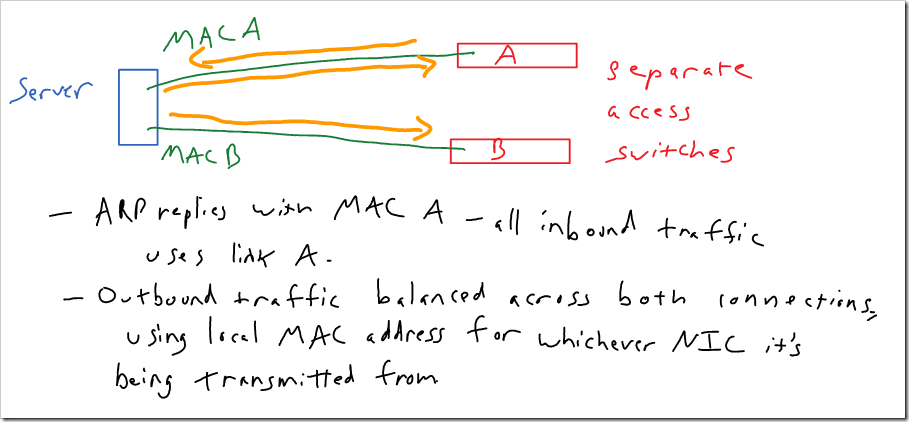
With transmit load balancing (mode 5), outgoing traffic is balanced across links, but all incoming traffic is sent to a single connection. The system replies to all ARP requests with the MAC address of the NIC that has been chosen to receive all traffic. So, all inbound traffic is sent to that NIC. Outbound traffic is balanced across both NIC’s. Outbound traffic from each NIC uses the local MAC address on that NIC (so the MAC address doesn’t flap between ports).
I’ve heard that there may be a few devices that don’t like seeing a different source MAC address on a packet from an IP than the MAC address that the IP resolves to in their ARP table. (So, the remote server has MAC address A in it’s ARP table for IP address X, but it receives traffic from IP address X from MAC address B). The IP Reflect feature in some EMC products might conflict with this. It wouldn’t surprise me if there are other devices that might behave strangely based on this as well.
During a failover, the surviving NIC takes over the MAC address of the failed NIC. So no ARP table changes are needed. The MAC address just moves to a new port in the MAC address table.
Adaptive load balancing (mode 6), is similar, but adds some additional intelligence to balance inbound traffic across both NIC’s. Instead of always replying to ARP requests with the same MAC address, the Linux kernel module used for bonding replies with the first MAC address for some ARP requests, and the second MAC address for other ARP requests.
Interestingly, when I was experimenting with this to see how it works, I found that it handles failures slightly differently than transmit load balancing. I couldn’t find any detailed documentation on what exactly happens when a failover occurs, so I tried it. When I used transmit load balancing, the surviving NIC took over the MAC address of the NIC that was previously being used to receive traffic. With adaptive load balancing, the surviving NIC did not take over the MAC from the other NIC. Instead - it sends a gratuitous ARP with the new MAC address. It sent this GARP only to specific neighbors on the subnet. So Linux must keep track of what neighbors it’s sent ARP requests to. I tried statically creating an ARP entry to see if the server would accept traffic destined to the MAC from the offline NIC on the surviving NIC. It appeared not to.
One additional item to note - if most or all of the inbound traffic to a server is coming from a single device on the subnet (the default gateway for instance).the receive load balancing won’t be overly effective. All traffic from that device will be sent over the same link to the server.
Pro’s:
- No configuration needed on switches
- HA / failover across multiple switches
- Good load balancing
Con’s:
- Potentially unexpected / somewhat unusual behavior if you’re not aware of how these bonding modes work
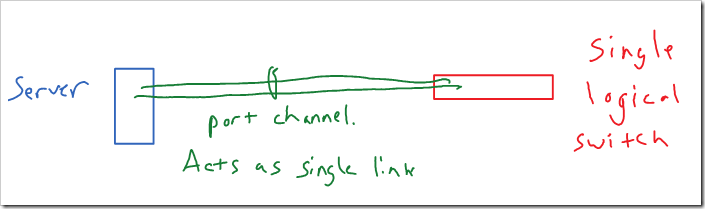
Port-channel
Unlike the other options I’ve covered today, this requires some support and configuration of the switches. The switchports have to be configured for the port-channel. The server and switch can use LACP, a standard protocol, to negotiate the link aggregation. Or it can just be statically enabled on the ports.
Both the switch and server see this logically as a single connection. So, the same source MAC address can be used across both physical links, without causing the MAC address to flap between the two ports. In the switch’s TCAM, the MAC address is associated with the port-channel interface rather than either of the physical interfaces.
Additionally - the switch and server can use more granular load balancing methods. Each side of the port-channel independently handles load balancing for outbound traffic. Switches can typically look at information up to the L4 TCP/UDP header. Based on the hashing, each connection is tied to a single physical link though, so individual connections can’t use more than a single link’s bandwidth.
Traditionally - both of the connections would terminate on single physical switch. However, switch stacking, Cisco’s VSS / vPC, and Juniper’s Virtual Chassis allow these physical connections to terminate on separate physical switches. With Cisco’s vPC, the switches have control planes that are linked (but independent) and synchronize some information. With the other technologies, the separate physical switches share a single control plane (stacking, VSS, and Juniper’s Virtual Chassis). So that’s still a single point of failure in my mind.
During a failure of one link, the same MAC address will continue to be used. The drivers in the OS and the switch will just remove one of the links from the port-channel, forcing all traffic to use the other link. This is configured as mode 4 bonding in Linux.
The risk of black holing traffic is less of an issue with port-channels. If the port-channel terminates on a single physical switch, all of the links will lose upstream connectivity if the switch does. With switch stacking / VSS / vPC / etc, the two switches are connected together. If one of the switches loses it’s uplinks, the control plane will send that traffic across the peer link (or stacking ring), and up through the uplinks on the other switch.
Pro’s
- Good active/active load balancing
- No MAC address or ARP table changes for single link failure
- Less risk of black holing traffic
Con’s:
- Requires configuration on the switch
- Connections must terminate on a single logical switch
So, you can see there are a variety of options here. The most effective option will depend on what kind of systems you are connecting in your data center, the nature of your traffic flows, your availability requirements, and the size of your traffic flows / whether link load balancing is needed. It’s also worthwhile to take into consideration your processes and work flows (if it’s feasible to have the network team configure port-channels on the switches for each server or not).
I’m sure there are some additional options out there that I’m not familiar with. If you have any other ideas - please comment, I’d love to hear from you.
That’s it for now. In the next post, I’ll discuss what options there are for the physical connections to the switches (end of row, top of rack, FEX’s and their placement, MRJ-21, etc).