
Data Center Server Access Topologies: Part 3, Switch Technologies
Edit: Here are the final links to all four of the articles in my Data Center Server Access series of posts: Data Center Server Access Topologies: Part 1, Logical Interface Config on Servers
Data Center Server Access Topologies: Part 2, Cabling Topology
Data Center Server Access Topologies: Part 3, Switch Technologies
Data Center Server Access Topologies: Part 4, Uplinks
In this post, I’ll go over some of the different technologies that access switches can use. I’ve briefly touched on these as they related to the topics in previous posts. This post will focus on things like stacking, Cisco’s VPC/FEX, VSS, and other vendor’s solutions.
Single Switch
If you don’t need high levels of reliability, one option could be to use a single chassis based switch with redundant internal components (access port linecards, uplink port linecards, supervisor or routing engines, power supplies, etc). This is still a single point of failure - but for many applications that’s acceptable. In a large scale grid environment, it might even be acceptable to go without the redundant components in the switch, and handle servers going offline in the job scheduler or software that’s managing the grid. This could result in a lower overhead cost wise to pay for the network connectivity for each server.
Advantages
Simpler
Cheaper - Could be acceptable to handle resiliency in higher level management software. You just have to be OK with the fact that a large batch of servers might go offline at any time. This could be OK in some HPC type environments (or maybe for something like Hadoop), if you’re willing to trade reliability for cost / speed (saving money on the network to buy more servers to increase the performance of the cluster).
Disadvantages
Little to no redundancy - still have a single point of failure for each server. Not acceptable in most data center environments.
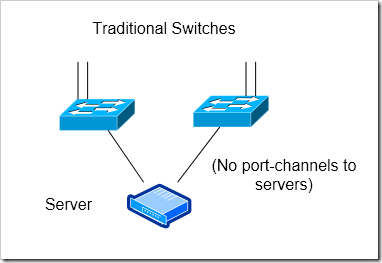
Traditional Independent Switches
The simplest reliable solution is to use two, completely independent switches. In a typical “inverted u” topology, both of these would have uplinks to the aggregation layer of your network, and would have no direct connections between them.
Advantages
Highly reliable - no state or resources are shared between the two switches - I like that the switches have completely independent control planes with this solution.
Disadvantages
More devices to manage
Can’t do port-channels to servers
Possibly higher cost per port - Depending on the platform you’re using, this could be somewhat expensive (when compared to using Cisco’s FEX’s). You’ll also need a total of at least four ports in your aggregation layer devices for each pair of access switches.
Chance of traffic being black-holing traffic with uplink failure - If both uplinks are lost on one of the access switches, all traffic from hosts that are active on that switch will be blackholed. I discussed this a bit in my first article in this series - basically, you’ll need to configure the switch to automatically down all of its access ports for dual-homed servers if it’s uplinks go down.
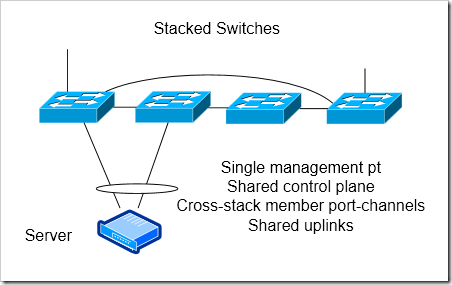
Switch Stacking
Most vendors support switch stacking as sort of a mid-range option between their lower end 1U switches, and their higher end chassis based switches. A number of access switches would be tied together, typically in a ring. The entire stack would have a single control plane. While the stack can survive the loss of a single stack connection or a single stack member, I still feel that the shared control plane represents a single point of failure (See my Thoughts on Availability). I’ve also heard plenty of horror stories of the software on switch stacks going awry or not failing over properly. Depending on what vendor’s solution you’re using, there might be some distance limitations on the stacking cable.
This is probably a reasonable option if your environment doesn’t need to be highly reliable, or need high levels of performance. This isn’t really an option for environments that need 10G connectivity down to servers.
Advantages
Fewer uplinks possible - If you want to increase your oversubscription ratio to lower costs (and reduce the number of port you need at your aggregation layer), you could have just two uplinks separated on different stack members. You get enough redundancy to survive a single uplink or stack member failure.
Cross Switch port channels to servers - Since the stack has a single control plane, it’s possible to have a port-channel that terminates on different stack members.
Disadvantages
Shared control plane - The stack has a single control plane. This will hurt you in case of software failures.
Stacking Connections Could be Bottleneck - The speed of the interconnection between stack members could be a bottleneck for environment that need high speed connectivity. Cisco’s StackWise+ is a 64 Gbps ring. It doesn’t make a whole lot of sense to have uplink connectivity that’s faster than that - so if you’re expecting your servers to need anything close to 64 Gbps to your distribution layer - look at another option.
Cisco’s Fabric Extenders - Single Homed
Cisco’s Nexus Fabric Extenders (FEX’s) are relatively cheap “external linecards” that connect back to a parent Nexus 5k or 7k. The FEX’s (the Nexus 2000 series) can’t do local switching, and are completely managed through their parent 5k or 7k. The FEX’s allow you to scale out more cheaply than you could with Cisco’s previous data center hardware. FEX’s can give you more flexibility when designing, making it easier to lower costs by increasing oversubscription or vice versa.
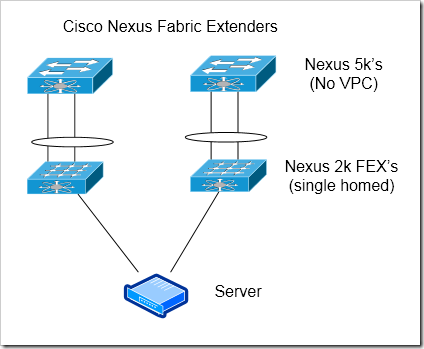
There are a variety of ways to construct a FEX access block. This option is using two completely independent groups of Nexus 5k / 2k’s. In essence - this is the second solution I listed, implemented with Nexus hardware.
Advantages
Completely independent devices
Can scale out more than chassis based switches - up to 1152 1G ports or 768 10G access ports off of each Nexus 5k. This lowers your per-port cost.
Disadvantages
No port channels to servers
Risk of blackholing traffic - each FEX is tied to a single 5k parent. If that 5k loses it’s uplink, all servers active on the FEX are black-holed.
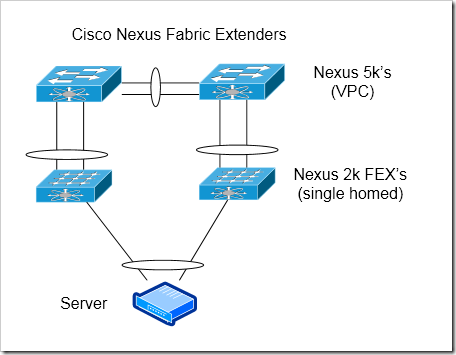
Cisco’s Fabric Extenders - Single Homed, with VPC
Each FEX will still be directly connected to a single parent 5k or 2k. However, the two parent devices will be connected together, and configured as a VPC pair. This gives us some additional flexibility.
Advantages
Port-channels to servers - With VPC, port channels that span FEX’s can be configured down to the servers. (Note - the first generation of FEX’s, the 2148, does not support port-channels. The 2148’s have a lot of limitations - avoid them if you can).
Scalability - still more scalable than chassis based switches are.
Better handling of uplink failure - Because the two Nexus 5k’s are connected together, an uplink failure is handled more gracefully. Traffic from the servers active on the switch that has lost it’s uplinks will be routed across the VPC peer link and through the uplinks on the other switch.
Disadvantages
Some sharing of state between the parent 5k’s or 7k’s - While it’s true that the parent devices aren’t completely independent, they still have separate control planes and are managed separately. This makes me much more comfortable using them than I am with using stacks or VSS.
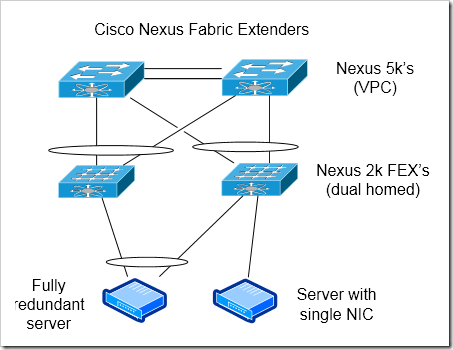
Cisco’s Fabric Extenders - Dual Homed, with VPC
In this model, each FEX is dual homed across both of the Nexus 5k or 7k parents. A peer link is configured between the two parent devices, and the two devices are configured as VPC peers.
Advantages
Resiliency for Devices with Single Connections - This is a great model for servers or other network devices that can only use a single connection. Devices that are single homed to a single FEX have only a single point of failure in this design - just the FEX itself (and the cable to the server / NIC).
Port channels to servers
Scalability
Better handling of uplink or parent devices failure - Dual homed servers won’t see a change (or have to fail over)
Disadvantages
Sharing of state between the parent 5k’s / 7k’s - Again, the parent devices aren’t completely independent. But, they are more loosely tied together, given that they each have their own control and management planes.
Cisco VPC
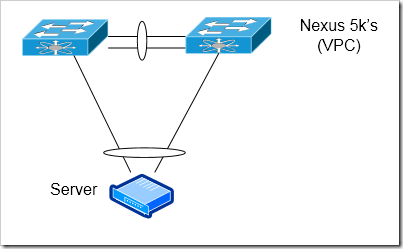
Ciscos Nexus 5k’s and 7k’s can be used at the access layer without the fabric extenders - though it’ll be much more expensive per port to use them instead of the FEX’s. This could be a reasonable option when you want a minimal level of oversubscription (and are willing to accept higher per-port costs in exchange for that). The Nexus 5k could act as a top of rack switch. The Nexus 7k can act as an end of row switch (though, in practice I think few organizations are willing to use an expensive Nexus 7000 as an access layer switch).
Advantages
Low Oversubscription rate can be obtained
If VPC is used between 5k’s / 7k’s, can use cross switch port-channels to servers
Disadvantages
More management points (versus FEX’s)
Expensive
Cisco VSS
In my view, Cisco’s VSS is somewhat similar to switch stacking. It just uses larger, chassis based switches, and is limited to two switches in the stack. The control plane is shared between the two devices. Right now, VSS is supported on the Catalyst 6500 and 4500 / 4500-X.
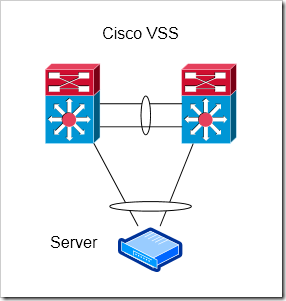
Advantages
Enables cross-switch Port Channels to Servers
Easier to use with L3 links than VPC - With VPC, the two switches look to be one from a L2 topology, but act independently at L3. There are some caveats with using a VPC pair with L3 adjacencies, VSS should work a little smoother in those situations. If you’re doing L3 down to the access layer, you can have a port-channel split across both devices, with a single adjacency to each distribution layer router (or just a single adjacency total if you’re using VSS at the distribution layer too).
Disadvantages
Shared Control Plane
VSS limited to two switches - VSS only works between two devices. Most vendors support a lot more than two devices with stacking. Given that VSS devices are generally chassis based (and can already handle several hundred connections each), this probably isn’t a big issue though.
Brocade VCS
I’m not nearly as familiar with Brocade’s products as I am with Cisco’s. Brocade has switches that support stacking, and have a technology they call “multi-chassis trunking” that appears to be similar to Cisco’s VSS. Brocade’s VCS fabric solution is pretty unique though, and looks very interesting.
Based on my understanding, a group of access switches are logically connected together using VCS (an extension to TRILL). This allows all of the uplinks to be forwarding (instead of having all but one of them be blocking for each access switch, as with spanning tree). Cisco has something similar to this using FabricPath, but Brocade’s solution appears to do a lot more.
Brocade’s VLAG’s allow port-channels across any switches in the VCS fabric. I also believe all of the switches have a single management interface.
I’d love to hear from anyone who has first hand experience with VCS - what do you think of it? How well does it work?
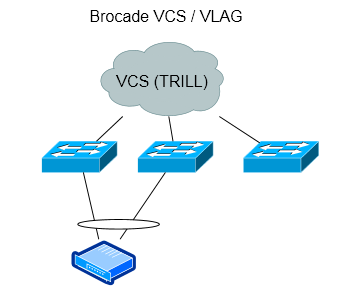
Advantages
Can potentially scale out more than VSS, VPC
VLAG’s allow port-channels across any members in the VCS fabric
Disadvantages
Single management / control plane?
This definitely hasn’t been an exhaustive or perfect list, but I think it covers a lot of the common options out there. I wanted to include some information about Juniper’s QFabric products - which I think are interesting (though, they don’t “scale down” very well - even in the smaller version of QFabric you still need hundreds of 10G ports for it to be cost-effective).
In the next article I’ll talk about connecting the access switches up to the rest of the network - where the L2/L3 boundary can be placed, spanning tree (and possible replacements), etc.