
Data Center Server Access Topologies: Part 2, Cabling Topology
Edit: Here are the final links to all four of the articles in my Data Center Server Access series of posts: Data Center Server Access Topologies: Part 1, Logical Interface Config on Servers
Data Center Server Access Topologies: Part 2, Cabling Topology
Data Center Server Access Topologies: Part 3, Switch Technologies
Data Center Server Access Topologies: Part 4, Uplinks
In this post, I’ll discuss some of the different switching options as far as where you place your access switches. What option is best for you is highly dependent on your servers, particularly, your density of servers per rack and how many connections you need.
Top of Rack Switching
One option is to have a 1U access switch on the top of each server cabinet. If your server density is relatively low, it may make sense to have top of rack 1U switches every other rack instead (or every third rack, etc), instead of wasting a 48 port switch on the top of a rack with 15 servers in it.
Traditionally, the downside of this in decent sized data centers is the large number of access switches that would have to be managed. However, there are some options to reduce that pain point. One option is using switch stacks. A group of switches would be connected together, typically in a ring, and would have a single management and control plane.
Cisco’s FEX’s have “dumb” FEX’s that are all managed through a single Nexus 5k/7k. In some respects, this gives you the best of both worlds by having a single management point, but having devices in each cabinet to minimize how far cables must be run. This could be particularly valuable for 10G server access, by letting you use significantly cheaper twinax cables from the server to the FEX (instead of SFP+’s with fiber). The FEX’s can connect back to their parent device using Cisco’s inexpensive FET modules (more expensive than twinax but still drastically cheaper than SFP+’s).
The large number of uplinks up to your aggregation layer also is a downside with using top of rack switching. FEX’s also address this problem to a degree by adding an additional L2 aggregation layer. The parent Nexus 5k / 7k aggregates the connections from a number of fabric extenders, and can have a single pair of uplinks to your real aggregation layer. Using switch stacks also can address this - you could have two redundant uplinks (on different physical switches), serving as uplinks for the entire switch stack.
Depending on the density of your server deployment, you might opt to have two redundant 1U switches per cabinet. Every server in the cabinet would then have connections to both. This could potentially support up to 48 servers per cabinet.
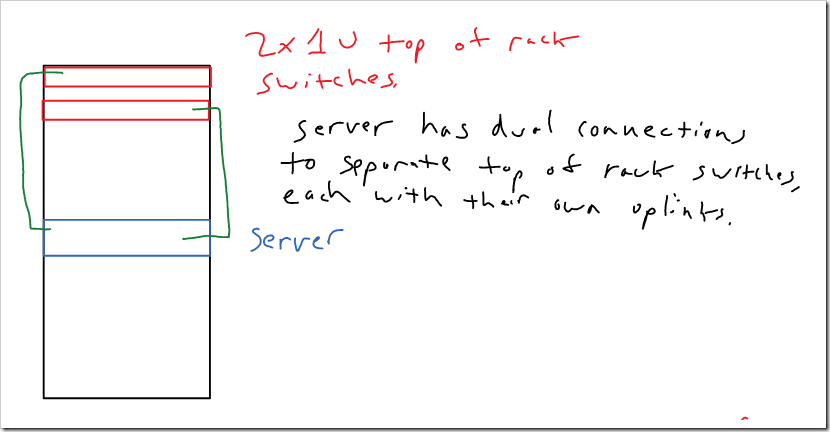
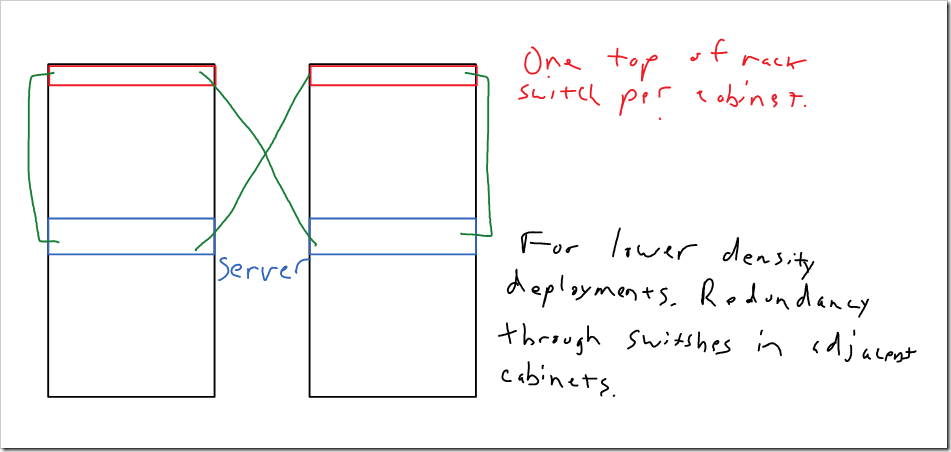
Another option would be to just have a single switch in each cabinet, with one connection from each server going to the switch in the cabinet, and one connection going to the switch in the next cabinet. This could support up to 24 servers per cabinet (assuming you’re using 48 port switches, each one supporting two cabinets). There are a number of ways this could be arranged. For lower density deployments, you could just up the number of cabinets that each switch supports.
Another option could be to use is “sort of” top of rack switching, is to use MRJ-21 patch panels in each cabinet. This would let you put a couple MRJ-21 patch panels in each cabinet, with a single cable running from each back to a chassis based switch. It looks like each MRJ-21 connection aggregates 6x 1 GBps copper connections. This lets you keep cable runs for individual servers within the cabinet, but still keep the intelligence / management on the end of row devices (chassis based switches). I’ve not personally seen this done. Brocade seems to have a few products that support MRJ-21 patch panels for gigabit connections. It seems like it would be an interesting option, though I don’t think it’s commonly deployed right now.
End of Row Switching
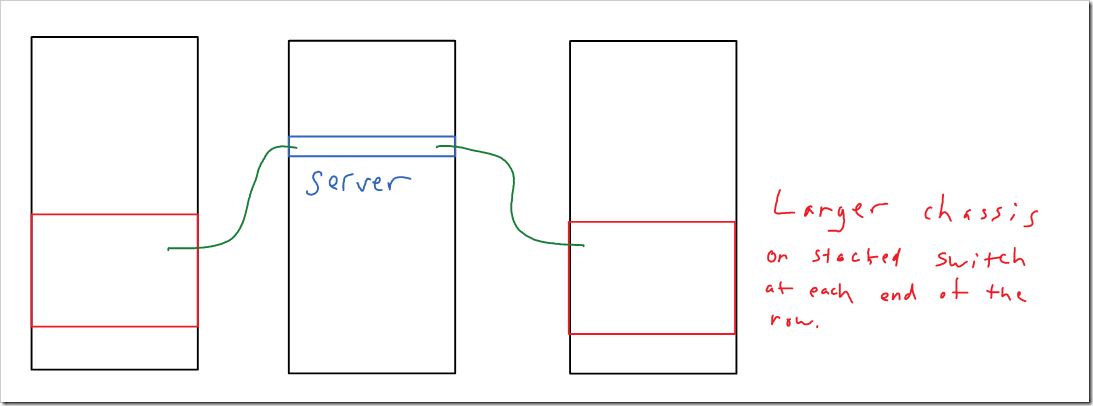
Next up is end of row switching. This is another fairly common option. Larger chassis based switches would be placed at the end of each row, and would handle the connectivity for all of the servers in that row. This results in fewer management points, and fewer uplinks to your distribution layer. Another upside would be the chassis based switches, which typically offer more redundant components (supervisors, power supplies, fan’s, linecards, etc) than 1U fixed switches. They may offer more advanced features as well. Instead of chassis based switches, switch stacks or Nexus 5k/2k’s could be used. Those would be cheaper than chassis based switches in most cases (though it would be also be missing some of the advantages of chassis based switches).
A downside would be longer cable runs, though they would still stay within the same row.
Centralized Telecom Devices
Another option would be to have all of the switches in a centralized location. Cable runs will have to be much longer. You likely won’t have significantly fewer management points than you would with end of row switching.
This probably doesn’t make sense for most data centers. I can see this sort of design being used for “specialty” networks within a data center, that may only support a few widely scattered servers that need a separate dedicated network for some use case. And I could make see this being the easiest design for very small data center that might only have a few rows of servers. But, for access switches supporting general production traffic - I don’t think this design has a lot of benefits.
What other design patterns / physical topologies have you seen deployed in data centers?